Explaining the Mechanics Behind an Advanced AI Music Generator
FreePik.com
In the rapidly expanding digital ecosystem, the demand for unique auditory identity has significantly outpaced the supply of affordable, high-quality composition. Brands, developers, and independent creators frequently find themselves trapped in a binary choice: settle for generic, overused stock loops that dilute their message, or face the prohibitive costs and logistical complexities of hiring professional composers. This acoustic void is now being effectively filled by the AI Music Generator, a sophisticated platform that translates semantic intent into fully realized audio productions. By analyzing the intersection of linguistic prompts and harmonic theory, this tool offers a glimpse into a future where the technical barriers to professional songwriting are effectively dismantled, allowing for direct translation from thought to sound.
The operational philosophy of this platform diverges from traditional sequencing software. Instead of requiring users to manually place notes on a piano roll or adjust oscillator frequencies, the system utilizes deep learning to interpret natural language. It functions as a bridge between abstract creativity and concrete audio engineering, synthesizing original waveforms that adhere to specific genre constraints and emotional markers. This analysis will dissect the technical architecture of the platform, outlining how it processes input, the specific workflow for generation, and the practical implications for professional media production.
Deconstructing the Architecture of Algorithmic Composition
The core engine of this technology relies on a “text-to-audio” model, which is distinct from earlier “Lyrics to Music” or MIDI-generation tools. While MIDI merely triggers pre-recorded sounds, this system generates the raw audio itself, allowing for a much richer and more organic texture. The AI has been trained on vast datasets of musical structures, enabling it to understand complex relationships between rhythm, pitch, and timbre. When a user inputs a request, the model does not simply retrieve a file; it predicts the most statistically probable sequence of sounds that matches the description, effectively composing a new piece of music in real-time.
Translating Semantic Prompts into Acoustic Waves
The initial phase of generation involves Natural Language Processing (NLP). The system parses the user’s input to identify key musical variables. A prompt containing words like “melancholic,” “piano,” and “rain” triggers specific parameter adjustments: a slower tempo, a minor key signature, and the inclusion of ambient texture layers. In my observation of the platform’s capabilities, the specificity of the prompt directly correlates with the accuracy of the output. The engine is designed to handle contradictory instructions—such as “upbeat sad song”—by blending major key progressions with somber instrumentation, a nuance that demonstrates a sophisticated understanding of musical duality.
The Role of Model Iterations V1 through V4
A critical aspect of this platform is the availability of multiple model generations, specifically ranging from V1 to V4. Each version represents a different balance between computational speed and audio fidelity. In testing these models, V1 appears optimized for rapid, rough sketching, suitable for quick background tracks where high-definition clarity is not paramount. Conversely, the V4 model is engineered for what the platform describes as “Studio Quality.” This advanced iteration shows a marked improvement in structural coherence, capable of maintaining a consistent melody over longer durations and managing complex arrangements without the “sonic mud” often associated with lower-bitrate AI generation.
Analyzing the Operational Workflow for Users
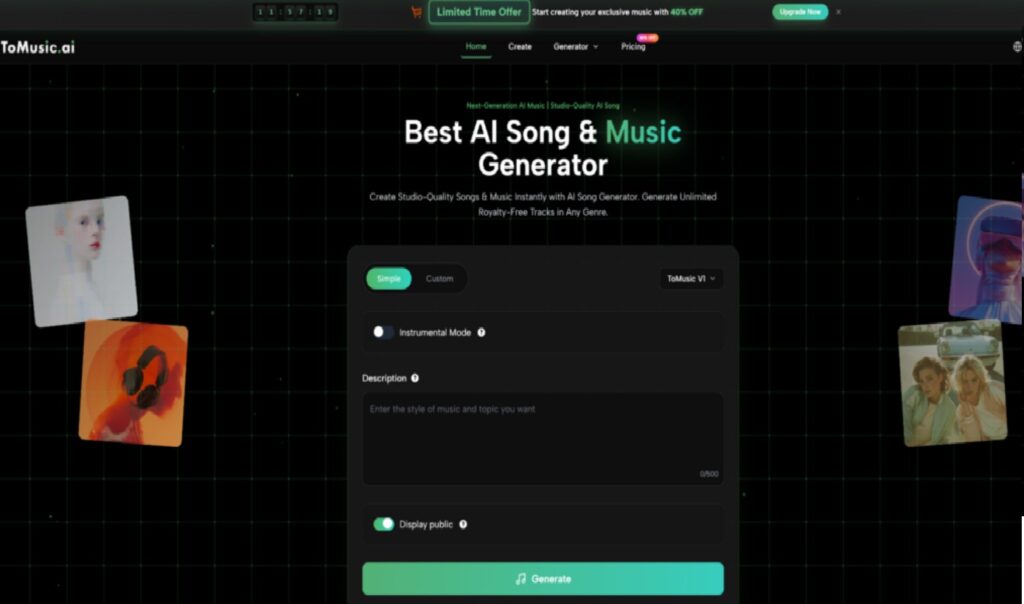
The user interface is constructed to guide the creator through a logical production pipeline. Unlike professional Digital Audio Workstations (DAWs) which can be intimidatingly complex, this platform simplifies the process into a linear sequence of decisions. Based on the official documentation and tool layout, the creation of a track follows a strict three-step protocol that ensures all necessary variables are defined before computation begins.
Step One Defining the Lyrical and Tonal Foundation
The process initiates with the content definition. Users are presented with a primary text field where they must establish the song’s narrative. This can be done by typing in original lyrics for Text to Music AI, or by providing a topic and allowing the system’s “Text to Lyrics” feature to generate the verses automatically. Simultaneously, the user must describe the musical style. This is not limited to broad genres; users can specify instruments (e.g., “acoustic guitar,” “synthesizer”) and moods (e.g., “energetic,” “chill”), essentially briefing the AI as one would brief a human producer.
Step Two Configuring Advanced Model Settings
Following the creative brief, the user must configure the technical parameters. This step involves selecting the specific model version (V1 through V4) appropriate for the task. The platform allows for the toggle of “Instrumental Mode” if vocals are unnecessary, which is often preferred for video background scores. Additionally, users can define the song’s duration and enable “Custom Mode” to access more granular controls, such as forcing specific tags or adjusting the “creativity” slider, which dictates how strictly the AI adheres to the prompt versus how much it improvises.
Step Three Executing Generation and Iterative Refinement
The final step is the execution. Upon command, the system processes the inputs and typically renders two distinct variations of the requested track. This A/B generation strategy is crucial as it provides the user with options regarding melody and phrasing. Once generated, users can preview the audio. If the result is satisfactory, the platform offers tools to “Extend” the audio—seamlessly adding more time to the track—or to download the file in the desired format. If the result is off-target, the user can refine the prompt and regenerate, treating the initial output as a rough draft.
Strategic Applications in Digital Media Production
The utility of this tool extends beyond simple novelty, offering specific advantages for various sectors of digital media. The ability to generate “Royalty-Free” music on demand addresses a major pain point regarding copyright strikes. For content creators, this means the ability to monetize videos without fear of revenue claims from third-party rights holders.
Customizing Audio for Specific Content Niches
The platform has integrated specialized generators for distinct content categories. For example, the “Story Song Generation” mode is optimized to follow a narrative arc, making it suitable for audiobooks or narrative podcasts. Similarly, “Relaxing Music” and “Brainrot Song” modes cater to specific social media trends. These preset modes adjust the underlying algorithmic parameters to prioritize certain frequencies and rhythmic patterns that are statistically proven to work well in those specific contexts, saving the user from having to engineer complex prompts for common use cases.
Utilizing Stem Separation for Post Production
One of the most technically impressive features available to professional users is “Stem Separation.” In a traditional workflow, separating a mixed song into its constituent parts (vocals, drums, bass) is difficult and often destructive. This platform includes this capability natively, allowing users to download the vocal track and the instrumental track as separate files. This is invaluable for video editors who need to lower the volume of the music during dialogue or for remixers who want to use the AI-generated vocals over a different backing track.
Evaluating the Commercial Viability and Limitations
While the technology offers significant advantages, it is essential to view it through a lens of realistic expectations. The platform operates on a tiered subscription model, and the capabilities available to the user depend heavily on their access level. The following comparison highlights the functional differences between the entry-level and professional tiers, which should guide users in selecting the right plan for their needs.
Comparative Analysis of Tiered Access Models
| Feature Category | Starter / Free Access | Professional / Unlimited Plan |
| Model Availability | Restricted to V1 Model | Full Access (V1, V2, V3, V4) |
| Audio Resolution | Standard MP3 Quality | High-Fidelity WAV & MP3 |
| Maximum Duration | Short Clips (approx. 4 mins) | Extended Tracks (up to 8 mins) |
| Commercial Rights | Personal / Non-Commercial | Full Commercial License |
| Generation Queue | Standard Processing Speed | Priority Fast Lane |
| Post-Processing | Basic Download Only | Stem Separation & Vocal Removal |
Navigating Technical Imperfections in AI Audio
It is important to acknowledge that despite the “Studio Quality” label, AI generation is not yet perfect. In my testing, while the instrumental tracks are often indistinguishable from human-composed electronic music, the vocal generation can sometimes exhibit “hallucinations”—singing words that were not in the lyrics or blurring pronunciation. Furthermore, the emotional dynamic range of a generated track may be more static than a song performed by live musicians who react to each other in real-time. Therefore, this tool is best utilized as a powerful assistant for background scoring, demos, and content creation, rather than a total replacement for human artistry in highly emotional or complex musical storytelling.





